Modernizing a fragmented legacy payment system.
I worked on a live farmer market platform where multiple payment gateways already existed, but the payment layer had grown through separate modules, duplicated logic, and low operational visibility. The job was not to bolt on one more gateway. It was to make a business-critical payment system safer to understand, debug, extend, and maintain.
Overview
The platform supported account management, market workflows, vendor onboarding, and payment collection. Payments were critical because they affected onboarding, recurring charges, operational billing, and gateway-specific rules. This was not a greenfield build. I was modernizing payment behavior inside a live legacy system where different modules had evolved differently over time.
The work had two responsibilities: understand what the system was actually doing, then create a safer path toward a centralized payment architecture without breaking production flows.
The legacy problem
The system already supported multiple gateways, but the architecture around them was fragmented. Payment logic had been implemented separately in account, market, and vendor onboarding modules. Business rules, failure handling, and operational behavior were inconsistent across the platform.
Payment state, internal records, and module expectations could drift apart, which made support and reconciliation hard.
The overall system reflected limited PCI awareness in how payment flows were structured and reviewed.
Logging was weak, debugging paths were shallow, and failure analysis depended too much on manual investigation.
Failure states did not flow into a dependable retry strategy, especially risky for recurring and auto-charge scenarios.
Each module had its own payment behavior with duplicated or inconsistent logic.
Even small changes carried risk because payment behavior was tightly coupled to legacy code paths.
What made it difficult
There was no useful documentation for the system. Understanding the current state required reading legacy code, running the application, tracing real flows, manually researching behavior, and talking to sales and business people to understand how the platform was supposed to work in practice.

The hard part was not drawing a better architecture. It was reaching it safely from a live, fragmented system.
First step: observability before refactor
I did not start by rewriting payment flows. The first improvement was centralized logging, metrics, and operational visibility. Without that, every refactor would have been based on assumptions. Observability made it possible to see how gateways behaved, where failures occurred, and which issues were critical enough to stabilize first.
Stabilization phase
Once the system was more observable, the next step was controlled stabilization. The priority was reducing operational risk. Critical issues had to be handled first, especially where failed payments, inconsistent states, or unclear recovery paths could create business problems.
- Critical data inconsistency issues were traced and handled more safely before structural changes were introduced.
- Failure cases were reviewed to improve recovery behavior and reduce silent breakage.
- Stability work built confidence so future refactoring could happen with less guesswork and less production risk.
Before vs after
Centralized architecture direction
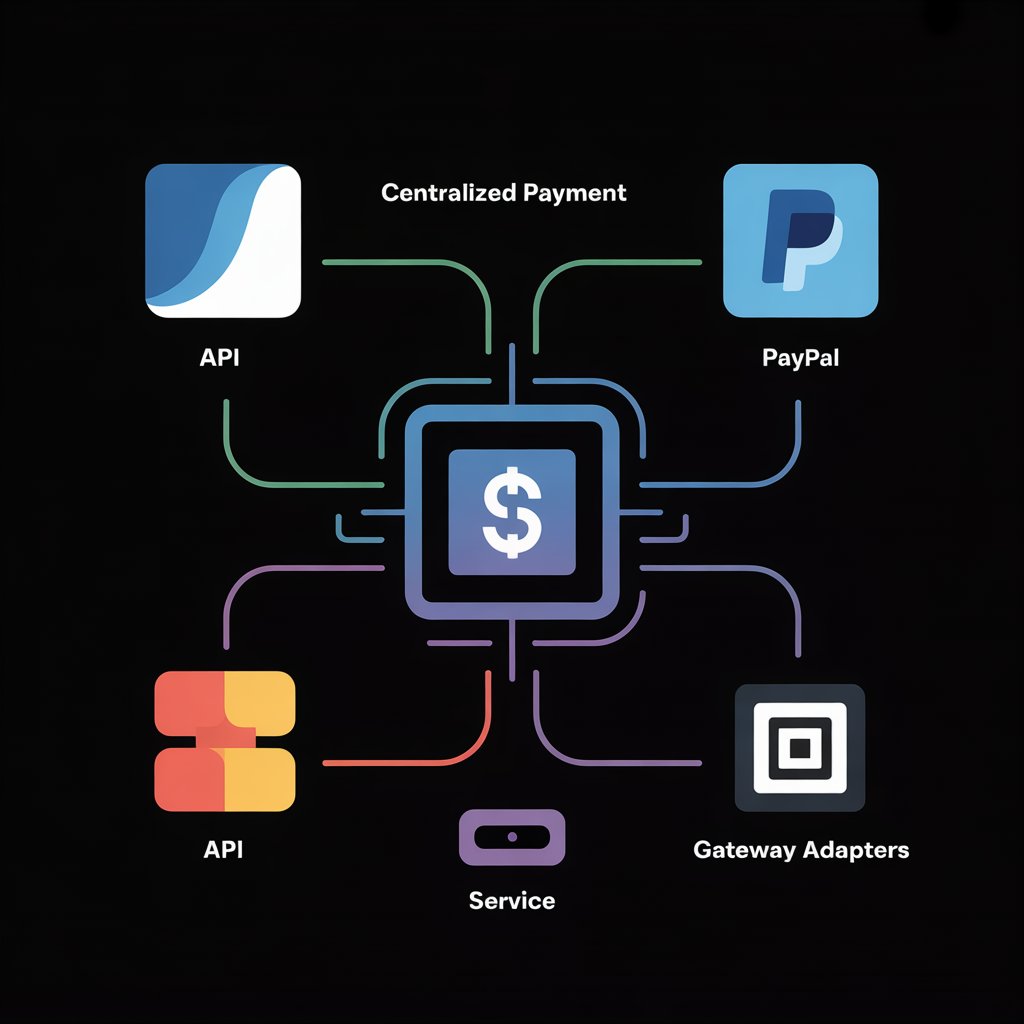
After the system was better understood and critical issues were stabilized, I planned a cleaner architecture path: centralize common payment concerns, isolate gateway-specific behavior, and create extension points that would make the system safer to scale over time.
A single direction for selecting and initializing gateway integrations instead of hardcoding behavior inside each module.
Validation, logging, failure handling, and transaction orchestration could live in one dependable place.
Gateway-specific behavior stays contained, which makes changes safer and future additions cleaner.
The system becomes easier to extend, safer to maintain, and less dependent on tribal knowledge.
Why this architecture matters
Payment systems age badly when common concerns are duplicated across business modules. Centralization improves failure handling, onboarding for future engineers, business flexibility in gateway decisions, and the ability to evolve recurring billing or auto-charge workflows without rewriting everything again.
Auto-charge and recurring payment reliability
Auto-charge flows make payment architecture more demanding than a one-time checkout. You need reliable retry behavior, clear failure states, and enough tracing to answer basic production questions quickly: was the charge attempted, what failed, what can be retried safely, and what follow-up action the business needs to take.
Challenges during implementation
The real challenge started after the architecture was clear. Implementation had to respect fragmented modules, duplicated logic, unclear ownership boundaries, live payment behavior, and business dependencies tied to the old system. Modernization work is rarely blocked by lack of ideas. It is blocked by the cost of changing a system people already depend on.
- Legacy modules had different assumptions about payment flow and state transitions.
- Duplicated logic made it hard to know whether a change was local or would alter behavior elsewhere.
- Missing documentation meant implementation needed constant validation against runtime behavior and business expectations.
- Because the flows were live, every refactor decision had to balance architecture quality against operational risk.
Outcome and impact
I am deliberately not inventing metrics here. The value of the work was qualitative but important: the payment system became easier to understand, easier to debug, safer to change, and better positioned for long-term gateway evolution and recurring charge reliability.
Key takeaways
In a legacy payment system, visibility matters before elegance.
Retries, logging, validation, and failure handling should not be scattered across modules.
Runtime behavior and business reality matter as much as code structure.
Auto-charge flows magnify the cost of weak retry and failure-state design.
Cleaner extension points improve delivery speed, supportability, and future gateway decisions.
Need to modernize a payment system without breaking production?
I work on SaaS platforms, payment integrations, recurring billing flows, and modernization efforts where reliability matters as much as architecture. If you need someone who can diagnose a legacy system, stabilize it, and move it toward a cleaner design, that is the kind of work I do.